Call the data editor in Stata with the commmand edit. The data editor is fine for looking at data and making slight adjustment, but its clunkiness makes it difficult to work with. It is, however, where you would import data. Before importing, you should check for a few things. Make sure your cases match across columns, especially if they comes from different sources. Also, make sure you name all your variables with easy to understand labels and no labels with just numbers (e.g. years), this will make it impossible for Stata to recognize column names.
Once your spreadsheet is ready, select all cells (ctrl + A), copy (ctrl + C), and paste in the first cell of the Stata data editor (ctrl + V). A prompt will pop up. It is imperative to choose the option: Treat first row as variable names.
The command clear deletes all the data in Stata. It is important in case importing data didn't work properly. If you want to drop only one variable, you can use drop variable. This is also useful in droping data according to set rules, for example drop if variable1 > X. This drops all data that does not meet that condition.
The command list variable is another good way to look at your data because it allows you to choose specific subsets. For example, you can choose to view variable 1 and 2 side by side list variable1 variable2 or impose a condition such as list variable1 variable2 if variable3 > X.
Sometimes, you need to create a new variable that does not exist in your original data. The command gen newvar = data generating process takes care of that. This command generates (gen) a new variable of your choice according to a specified formula or containing a value. So, you can either assign the new variable a value directly, use a formula such as growth rate or apply a transformation such as log10.
If instead of generating a new variable you simply want to modify an existing one, recode oldvar coding rule, into(newvar) is the way to do it. Recoding means that you apply a formula to an existing variable to create a new variable. For example, to create a categorical variable with three categories you would type: recode oldvar 0/100=0 100/1000=1 1000/10000=2, into(newvar).

This is a hypotheticla dataset (using presidential election data). The first two columns contain the data that will be plotted in the scatter plot. The third column contains the names used for labeling each observation in the plot. The fourth column is an alternative labeling scheme whereby we keep only incumbents that won. The last column is the positioning values. Remember, positioning operates according to clock positions.
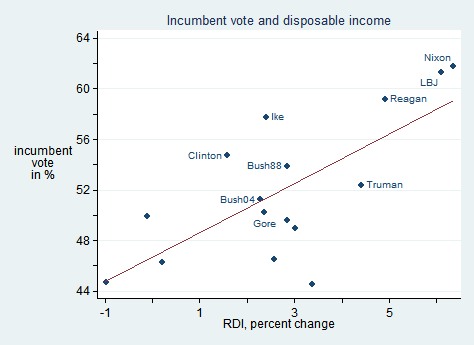
Now, plot as usual. Use the commands mlabel with incvote as a variable to label all observations or label to label only observations above 50%. Use mlabvpos(pos) to position the labels accordingly.